Citrine | VirtualLab
A powerful AI system that lets your researchers find better results more quickly, by conducting virtual experiments before they go into the lab
How it works:
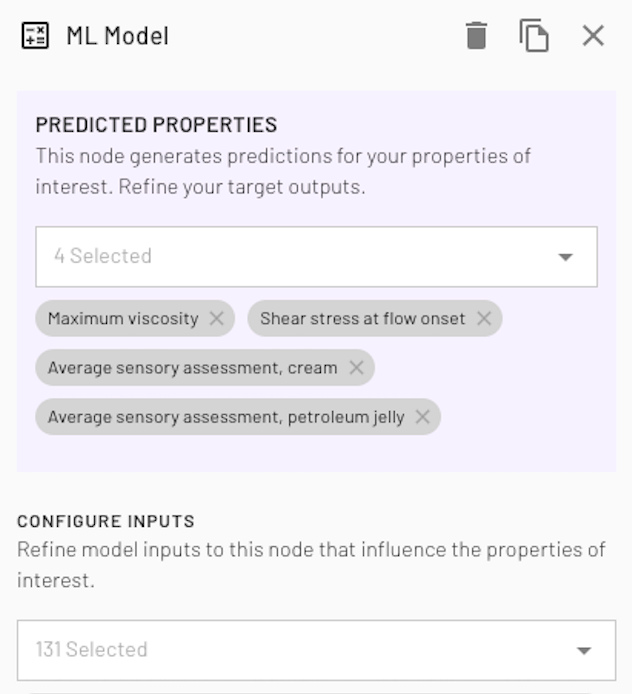
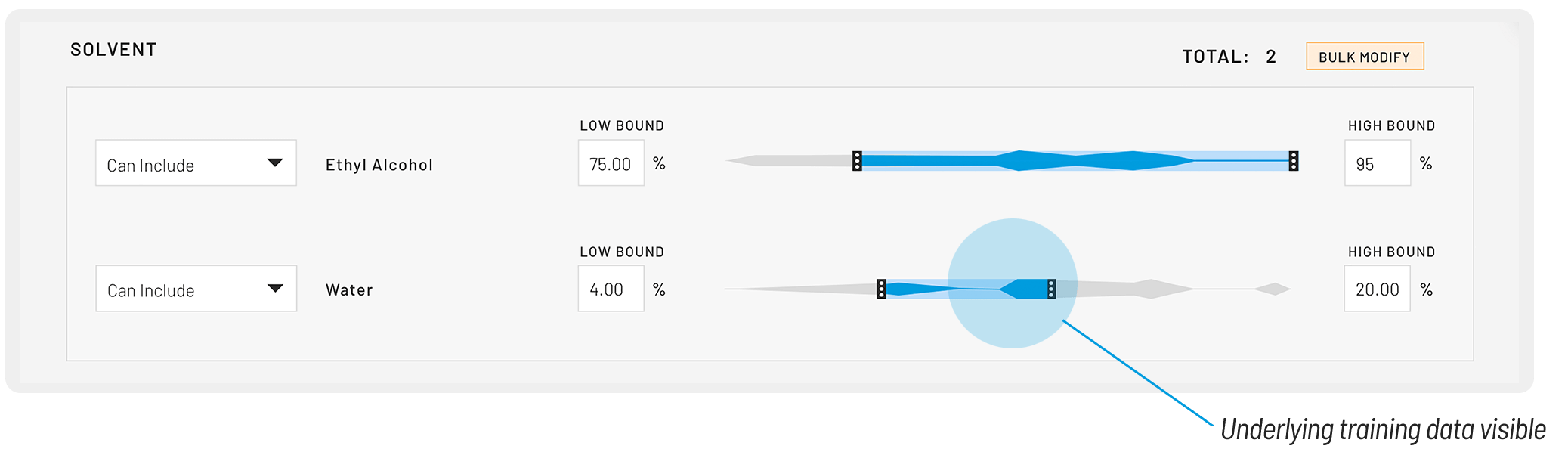
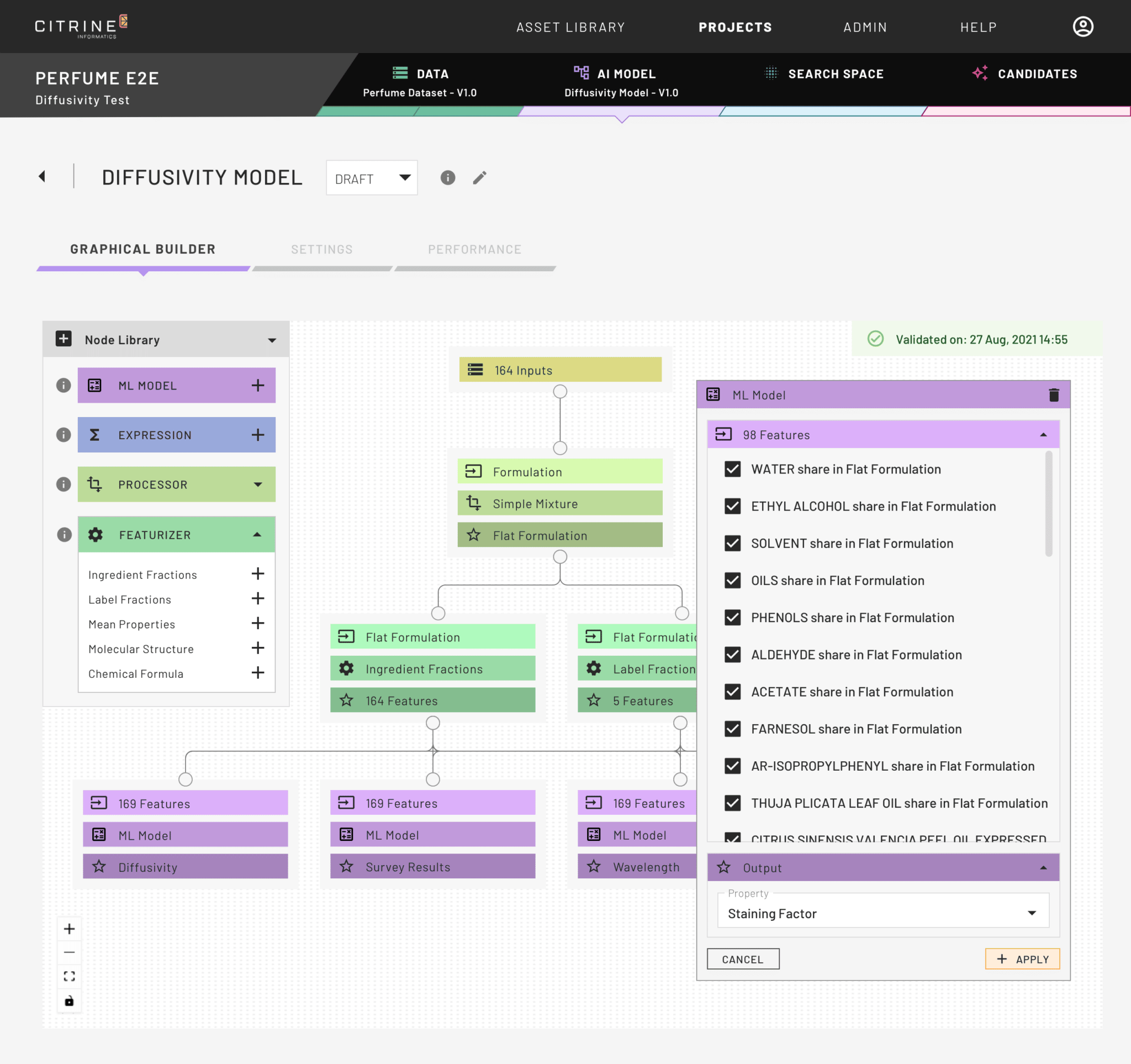
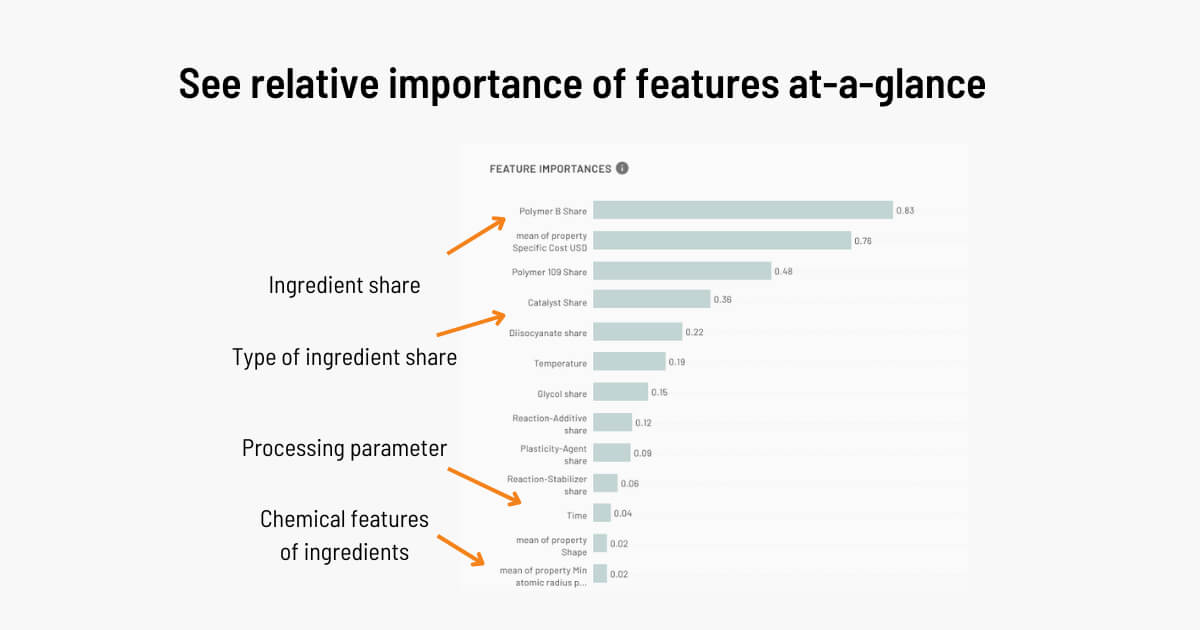
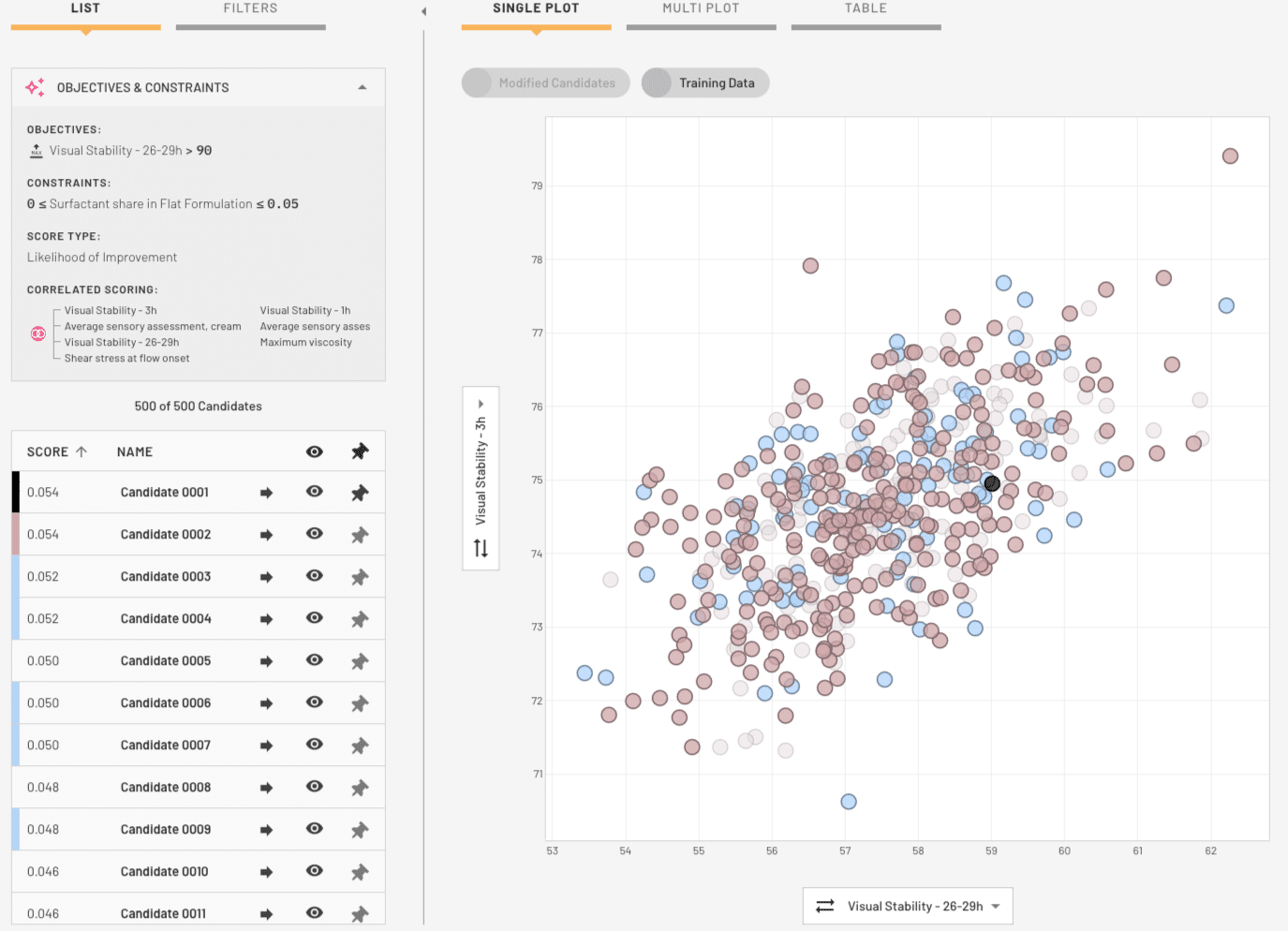
Detailed feature impact plots help you to unpick the effects of different raw materials, process parameters, and molecular features on your target properties. This helps companies supplying raw materials highlight the impact of their products, and helps Product Experts understand their domain in more detail.
“We understand our own laboratory more than before. It’s fun to work in this way.”
— Oliver, Technical Application Lead
FAQs
-
How does AI work?
There are different types of AI, but at a high level, the machine learning models that Citrine Informatics use essentially look for connections between inputs (raw materials, processing parameters) and outputs (final material properties) and then creates an algorithm to predict the outputs based on the inputs. However, predictions are not as effective if you don’t know how good your prediction is. Therefore, the uncertainty of the predictions is also estimated and this is the extra information that our customers leverage to decide which experiments to take to the lab next.
-
What machine learning techniques are commonly used in materials informatics?
Common techniques include supervised learning (e.g., regression, classification), unsupervised learning (e.g., clustering, dimensionality reduction), and reinforcement learning. Deep learning methods, such as neural networks, are also increasingly used for complex data types like images and simulations, though in most cases the availability of data limits use of deep learning techniques. Citrine Informatics’s sequential learning approach represents a unique optimization framework that is data-efficient and can handle bigger, real-word problems (dozens of variables, multiple objectives, noisy data, and real-world constraints) with ease.
-
What type of AI models do Citrine use?
Citrine uses a new generation of optimization frameworks that build on Bayesian Optimization’s (BO’s) foundations while overcoming many of its limitations. By swapping the Gaussian Process Regression for a more scalable and robust model (random forests with advanced uncertainty quantification), Citrine’s platform retains the data-efficiency and intelligence of BO but gains the ability to handle more challenging, real-word problems (dozens of variables, multiple objectives, noisy data, and real-world constraints) with ease. It provides results that are not only optimal but explainable – a critical factor for trust in AI-driven design in the research community. Different algorithms, such as Gaussian Processes and Random Forests can be used on the platform and the results from the most accurate model will be used.
-
What R2 do you need in your materials AI model?
R2 is a measure of prediction accuracy commonly used to assess model performance. R2 compares predicted versus actual values across the whole search space and gives an average value for the difference between them. Historically it has been important to improve the accuracy of a predictive model as high as possible (1 is the highest) before using the model. However, in the AI-driven experimentation process, a sequential learning approach is used, where you start with small amounts of data and at first use the model not to just predict the properties of candidate materials, but to estimate the uncertainty of the model predictions across the search space. In this way you can carry out experiments in places that look promising in terms of materials properties but where those predictions are highly uncertain. This generates the most valuable data to improve the accuracy of the model so that it can then predict the best materials with more confidence. This approach is counter-intuitive for many researchers, but has been shown to be the quickest way to success. We recommend going to the lab and running the next set of experiments as soon as R2 reaches about 0.3. We commonly see a reduction in the number of experiments carried out to hit targets of 50-80% using this method. Read more about this in our blog.
-
Why is Uncertainty Quantification important in Materials Informatics?
When a researcher takes an experiment to the lab they hope it will hit their targets, often based on a gut feel for how confident they are that it will be successful. Design of Experiment techniques are often used to plot out a grid of experiments to cover a search space, but these approaches have no idea which experiment will be successful. With Materials Informatics and AI, as well as predicting final material properties, the uncertainty of those experiments is also estimated. The researcher can then decide to take to the lab experiments with a medium certainty of great properties, or a high certainty of mediocre properties or both. The experiments in an area of the search space with high uncertainty are particularly good for generating data that can train the AI model to be more accurate. In this way a researcher can be very strategic and navigate an efficient sequence of experiments to get to target properties using the least time and resource.
-
What is feature importance?
Features are the different kinds of data that you train an AI model on. Feature importance is a way of representing which of these are being used to by the model to predict a final property. For example, if predicting the tastiness of a biscuit, the amount of sugar and amount of vanilla essence might have a high feature importance and the brand of butter used might have a low feature importance. This blog post explains how you can learn from AI models as well as teach them.
-
What is a search space?
A search space, sometimes called a design space, is a representation of all the different allowed options for the combinations of inputs to an AI model. For example, a search space can consist of the allowed ingredients, the allowed processing parameters, perhaps even some rules about which ratios of ingredients are allowed, or how much of one type of ingredient is allowed. Researchers set up search spaces to make sure the AI models are predicting properties of feasible materials, both from a business and physical perspective. Read more about this in our blog.
-
What is transfer learning?
Transfer learning is a machine learning technique where a model trained on one task is adapted to perform a related task. For example, you may know that the fracture toughness of a material is related to its tensile strength. If you have lots of data to predict tensile strength, and not a lot of data to predict fracture toughness, you can model tensile strength and then feed in the predictions of tensile strength into the model predicting fracture toughness. It is also used in raw material substitution. If a model learns that a particular molecular feature is important for predicting a property, it can then predict the performance of a substitute ingredient in the formulation by examining that molecular feature in the new ingredient. In this way, the Citrine platform can predict the properties of new formulations using completely novel ingredients.
Learn more:
Case Study

Machine Learning Accelerates Materials Development
Learn how Citrine’s platform supported Panasonic as it developed new organic semiconductors.
Case Study

First-to-market High Strength 3D Printable Aluminum Alloy
Explore how HRL reduced development time from years to days using the Citrine Platform.
Case Study
Rapidly Screen Polymers Using AI
Discover how CVM screened 2500+ polymers in only 5 months. Researchers now know the most promising 10 polymers for a given target.
See for yourself:
