We get asked about the accuracy of our models all the time, and it is totally understandable why… but we think people should be asking a different question. This blog outlines why accurate uncertainty calculation is key to achieving business goals with AI.
How accurate are your models?
This question regularly comes up in conversations with prospective customers. Understandably, they want to understand how “good” our AI methods are and be able to compare them to other ways of working or other AI platforms. However, this is a difficult question to answer in two ways.
Firstly, the accuracy of the model as measured by R2 or RMSE (standard methods for evaluating fitting accuracy of a model to the underlying data) is reliant on the amount and distribution of the training data. As we haven’t seen the training data yet, we can’t promise anything.
Secondly, we just don’t think that R2 is what matters most when it comes to achieving the business objective.
What does R2 Measure?
R2 and RMSE both calculate an average value of accuracy over all the data points in the training data. This means that the predictions could be half terrible and half perfect and the model accuracy would still look OK. It also doesn’t tell you what the accuracy of the model will be in areas outside the training data. And lastly, it is static; it can’t tell you how the model will perform if you apply it to a related but different project. Our team does look at RMSE, but they use it as a way to see whether a refinement of data or an addition of domain knowledge has helped or hindered the model they are working on. This paper in the Journal of Chemical Information and Modeling does a good job of explaining this in more depth.

What is the business goal?
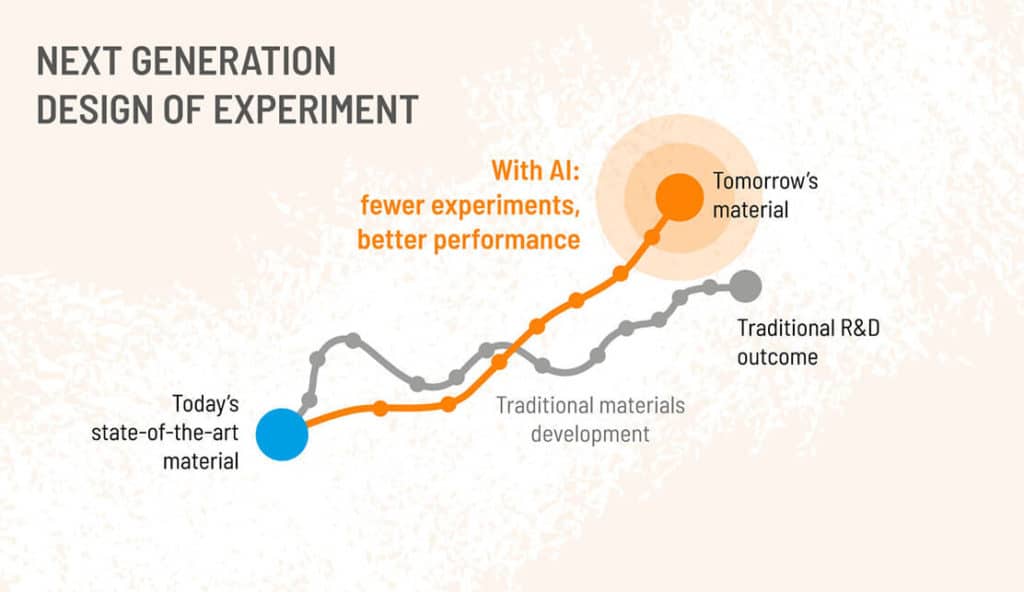
Ultimately, the purpose of the Citrine Platform is to suggest what experiment to do next. A company is not going to see a suggested recipe for a product and immediately synthesize it at scale and ship it to a customer without first testing it. And the reason companies use the Citrine Platform is because it guides researchers through a series of experiments to reach their targets more efficiently than purely human-led scientific intuition or traditional Design of Experiment (when there are many dimensions to consider). Fewer experiments = faster discovery.
What makes a good next experiment?
The next experiment you do should either deliver a high performing material, or significantly improve your model by getting you data in an area where your model is currently highly uncertain. To understand which experiment delivers this to you, you need to understand the uncertainty of the model, not as an average, but for every material candidate in the search space. So the question of how “good” your AI models are becomes “How well can you quantify the uncertainty of model predictions for every material candidate?”
How does the Citrine Platform quantify uncertainty?
The basis of the quantification is readily available to look up in the literature. As a high-level summary, it actually trains lots of AI models to try and fit subsets of the data and then compares their results. Where the models give similar results to each other, the uncertainty is low. The uncertainty then has to be scaled so that it more accurately represents the uncertainty of the property. While the Citrine Platform’s ensemble methods are based on the literature, they have been refined and polished by our team of data science experts over the 8 years we have been working in this area, so that they are as effective in practice as they are in theory. That polish is what puts us ahead. We regularly benchmark our methods against the latest and greatest, and find that our methods continue to perform as well or better on real materials and chemicals datasets.
We also get asked other questions in the same vein
How do our methods compare to Design of Experiment?
In materials and chemicals challenges there are usually many dimensions to optimize simultaneously. This is where AI shines. AI-guided Sequential Learning is essentially highly optimized Design of Experiment, with AI providing information on whether there is a likelihood of achieving the targeted properties and uncertainty quantification providing information on how accurate that prediction is. Read more about our methods here.
With error bars on 5 different properties, doesn’t that mean that the error overall is high?
Again, we need to think about the purpose of the predictions. The platform ranks candidates to help you decide what experiment to run next. In the case of a correlated systematic error, it will apply to all candidates and the ranking is still valid. In the case of uncorrelated errors, then those errors are just as likely to cancel as they are to compound because of their independence.
With model accuracy low in areas where training data is not available, how can AI help us discover something in new areas of chemistry?
This comes back to Sequential Learning. The Citrine Platform supports a process of iterative learning. The data gained from the small set of suggested experiments is fed back into the model which improves its accuracy across more of the search space. Step by step the model becomes more accurate in areas of new chemistry and locates candidates with a high likelihood of meeting targets. Read more about Sequential Learning here.
Your platform uses “LIKELIHOOD OF IMPROVEMENT” and “EXPECTED IMPROVEMENT” to evaluate material candidates. What do they mean exactly?
Our likelihood of improvement score measures the likelihood that the candidate will exceed an established performance baseline.
Expected improvement looks at the likelihood of a candidate falling above the target value, but it also takes into account how far above the target it is likely to be. So expected improvement is used to find those candidates that have a chance (even if small) of hitting it out of the park.