Data standards are important to make sure that you get the most from your data. As we digitalize industry, following standards makes data easier to work with and thus much more impactful. Since 2016, a group of data principles has been nicely articulated using the acronym FAIR. The principles are not particularly novel; they are mostly common sense. But their easy-to-understand articulation has helped numerous countries and organizations to sign up to promoting and using them. This blog will focus on how these principles apply in industry, rather than public research organizations.
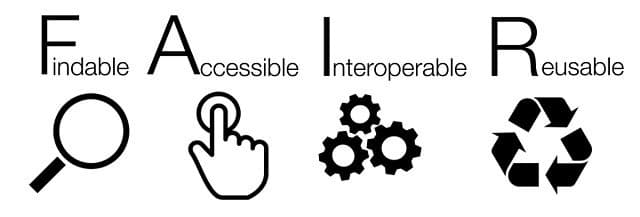
WHAT DOES FAIR STAND FOR?
Fair stands for FINDABLE, ACCESSIBLE, INTEROPERABLE, REUSEABLE.
WHAT DOES THAT MEAN?
Wikipedia has a great explanation here, but this is the short, friendly version.
FINDABLE
Every resource should have an address.
Data (whether data or metadata) is labelled with a unique identifier and registered in a searchable system. Rich metadata (clearly linked to the identifier of the data it describes) is used to aid in discovery. Be generous in your annotations: you don’t want a researcher to miss data because they searched for viscosity instead of fluidity. In summary, if you put data into a system then you can locate it again later, preferably using one of many different paths.
ACCESSIBLE
Something is at that address.
It should be easy to retrieve the data from the system, provided you have authorization to view the data. This reflects a combination of concerns including defining how a user can request the information they want and, if there is some compelling reason the data cannot be shared, the user can find out why. It doesn’t do much good to know a resource is there if you can’t get access to it.
INTEROPERABLE
The file you get back is well formatted.
Data should be stored using a common language and vocabulary so that it can easily be combined with other data, processed, stored, and analyzed. If the file is a tabular format, such as CSV (Comma Separated Values), then the column definitions are documented clearly. If you need software to read a file, such as Microsoft Excel, then it is clear how to get that software. You shouldn’t end up with some mystery set of bits you can’t work with.
REUSABLE
The data is understandable – not just readable.
So that other researchers can use the data in the future, rich metadata should be used. Make sure to include information about how the data was gathered, like test standards etc., so that future researchers will be able to trust that data and know whether it is comparable to other data. Writing documentation is an investment. Provide a data usage license when releasing the data.
HOW DOES THIS APPLY IN INDUSTRY?
The first step in any research project is gathering prior art. Operating on a fixed timeline, the researcher budgets perhaps 5 % or 10 % of their time early on towards collecting and understanding what came before. When your organization’s data holdings are FAIR, that budget goes a lot farther. AI compounds this impact: more data powers (generally) better predictions. With transfer learning, where data from adjacent research projects can be used to inform your project via well-structured AI models, it becomes vital that your colleague labels data carefully. In materials and chemicals each data point can easily cost tens of thousands of dollars to acquire. Following FAIR data principles amortizes that cost.
WHAT DOES THIS MEAN FOR THE DATA PLATFORM THAT YOUR COMPANY USES?
FINDABLE
Any data platform your company uses needs to have a system to assign unique global identifiers to all data and metadata. It also needs to support you adding rich metadata, allowing you to search for information when you don’t know exactly what you are looking for.
ACCESSIBLE
Authorization and authentication systems are especially important in an industry where valuable data represents a competitive advantage over rival companies. Any data platform you use should have security in depth, and good search and filtering facilities to retrieve data. It should have data resilience baked in, so that you can get the data when you need it and so that it’s safe and secure when you don’t.
INTEROPERABLE
An organization has a wide variety of data resources. Simply putting them in a central repository is not enough; you need to keep track of how to read the files. If you are using a third party to organize and store your information, you should have confidence that their computing hardware and underlying storage is reliable, and if you part ways, the resources you entrusted to them are not locked up in proprietary formats.
REUSABLE
This is the goal that is most often at odds with maintaining high business velocity. People decry having to spend time today to properly annotate their work, despite the fact they celebrate the people whose work they can reuse exactly because of such notes. Meeting that tension requires tools to make that process efficient and seamless, such that rich metadata is collected with the data themselves, and not as some afterthought. The more your researchers’ thoughts can be structured and consistent across projects, the easier it becomes to evaluate what is relevant for next year’s goals.
WHAT DOES CITRINE USE?
Citrine has developed its own materials data format called GEMD (Graphical Expression of Materials Data). You can read all about GEMD here.
WHY DEVELOP OUR OWN?
- Metadata is varied, detailed, and essential for Materials and Chemicals data. We needed a way that scientists could describe their data very thoroughly, with enough flexibility to encompasses properties from flavor to fracture toughness, while maintaining enough structure, that related data could still be connected.
- Scientists go on a journey as they experiment and find new results. New findings sometimes result in a change of direction. We needed a data model that could cope with this – one where it would always accept new data. In traditional relational databases, adding data that a database wasn’t initially set up to accept is a pain and time consuming.
- Materials and chemicals production typically require more than one processing step, and processing histories are directly connected to material and chemical outcomes. We needed a way to express the input of ingredients and the processing parameters over time.
HOW DOES THIS HELP ME?
Using the Citrine Platform to store, use, and analyze data has lasting benefits:
- Data accessibility – stop hunting through obscure spreadsheets
- Knowledge management – reuse your data
- Data aggregation – pull data from many sources into one place
- Spot trends and relationships through visualization
- Leverage the data in AI