Key Takeaways
- AI isn’t magic, it just identifies relationships between inputs and outputs.
- With the right AI platform, you don’t need as much data as you think.
“We need data to do AI” and the phrase “AI-ready” data get used a lot. Let’s first establish what they mean.

AI looks for patterns in cause and effect. So it needs detailed, accurate information on the inputs, in our case, a full materials and processing history of the product, and outputs, the properties of the final product that you care about. Importantly it needs to know which inputs lead to which outputs, you need a sample ID to match sample preparation with test results. That’s it. Simple.
Going forward tip: Make sure that all measurements from now on, connect sample preparation data with test results.
Data Quality Over Quantity
Let’s unpack what we mean by detailed and accurate information. Materials and chemicals and products are often made in stages, there is a process flow and raw materials or ingredients can be added at different stages in different amounts. The more detail that can be recorded, in terms of amounts of ingredients, processing parameters, etc., the better. AI can take all the data you throw at it and it will simply ignore anything that doesn’t correlate to the properties you are interested in. However, just like any other software program: garbage in, garbage out. So the data does need to be accurate. It needs to be measured in the same way, to the same standard. Measurements need to be converted into the same units and any typos or badly calibrated measurements should be excluded.
Going forward tip: Make sure that test standards and processing conditions are recorded every time.
Data Diversity
AI makes predictions over a “search space”, meaning that it has a range of inputs it is allowed to consider and it predicts outputs based on the allowed inputs. So for example, when predicting the tastiness of a cake, you might allow certain ingredients in your search space e.g., % butter, % sugar, and not allow others, % mustard. Each ingredient and processing condition is a dimension in your search space that can be varied. AI works best when it is fed a diverse range of data points across the search space. That means both that the data points are spread out, but also that they include failures as well as successes. The AI needs to learn what doesn’t work, so that it can rule things out and only present you with good suggestions. Unfortunately, historical data in companies do not usually include all the experiments that went wrong.
Going forward tip: Reward employees for recording all data, not just successes.
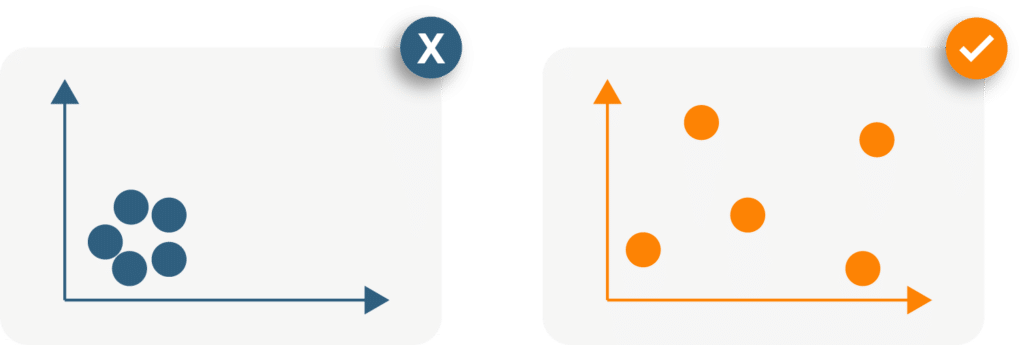
How much data do you need?
It depends. Standard engineering answer! Citrine has supported customers who have started projects with no data! They first created a small grid of 20 experiments to run, trained an AI model on those, and used AI to suggest the next experiments and so on. Citrine’s AI calculates the uncertainty in its predictions across the search space, so it can tell you which experiments would give it the most useful information. If you already have the data but it is really time consuming to digitize, you can use the AI model to tell you which data is worth your time digitizing.
30 diverse data points is a great starting point, 100 even better. But if all 100 of the measurements were done using just 3 different formulations, then that data is not diverse, it is clustered and it won’t be as useful as the 30 diverse data points.
How can the Citrine Platform make progress with such little data?
Citrine Informatics specializes in working in Chemicals, Materials and Products. From the start, more than a decade ago, it was known that Citrine would need to work with small data sets. So while the likes of Google and IBM were working out how to mine “Big Data”, Citrine were working on how to use what is available in the average research lab.
Using the knowledge in the heads of product experts
Citrine believes that it is important to empower product experts to use AI directly. That way, they can add their own knowledge to the AI, in much the same way they train a new member of the lab. This improves model accuracy and captures their knowledge in a way that it can be reused by other experts in the future. In concrete for example, the ratio between cement (and other binding agents) and water, is important for its compressive strength. It is easy for a product expert to tell the AI that the ratio is important and then that ratio will be used as an input to the AI’s model. The experts can also narrow their design space so that computing power isn’t wasted looking at unfeasible options. For example if a furnace can only go up to 750 degrees Centigrade, then there is no purpose of calculating predictions for a material sintered at 800 degrees.

Getting extra data for free
Chemical formulas and molecular structures tell a scientist a lot of information besides which atoms are where. For example you can calculate the molecular weight, or the number of hydrogen bond acceptors etc. The Citrine Platform is chemically-aware. It recognizes Chemical Formulas or Smiles notation (for molecular structures) and converts these into approximately 130 extra data points for each ingredient.

Joining data together
Sometimes there have been previous projects carried out measuring the same properties on similar materials. The AI can learn from this. If it can work out what aspects of the composition or processing are affecting the final properties, it can use that knowledge to predict the properties in the new materials. This is called transfer learning, and the Citrine Platform is set up to take advantage of this.
How Citrine Helps
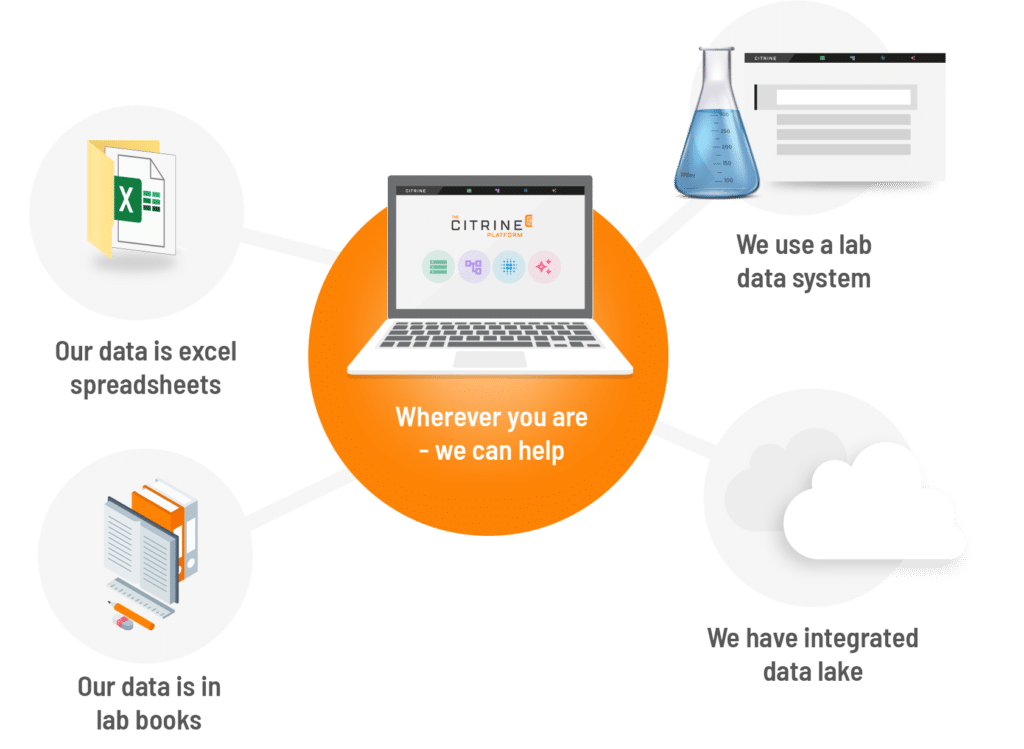
Citrine has been working with companies to get business value from their data since 2013. The team is experienced and has seen data in dusty notebooks, well-guarded personal spreadsheets and siloed in different LIMS systems. Citrine Data Preparation Services can both help prepare your data strategy and help you get data on to the Citrine Platform.
Like to learn more?
Set up a conversation with a member of Citrine’s Expert Services team. Citrine’s Experts all have deep academic and professional background in applying data science and data engineering to Product Development.
Contact us to find out how quickly you can start fully leveraging your data.