Artificial Intelligence is a powerful tool with enormous potential business benefits. However, in the materials and chemicals industries, there are unique challenges to overcome.
1. Small Data
“BIG DATA” is a phrase commonly associated with AI and machine learning. Companies with millions of customers or thousands of sensors can quickly and cheaply amass billions of data points. In materials and chemicals, each data point can cost months of time and tens of thousands of dollars. A machine learning approach for materials therefore has to be tailored to small, sparse data sets.

Citrine Informatics has overcome this challenge by:
- Using the knowledge in researchers heads to point the AI in the right direction
- Enabling transfer learning and domain knowledge integration
- Developing a chemically-aware platform that uses scientific understanding to generate extra data automatically
2. Diverse Data Sources
Materials and chemicals data comes from many different sources—test data, simulation data, reference data, supplier data sheets—and in different formats—microstructure images, processing instructions, chemical formulas, x-ray diffraction data, etc.

To use this diverse data, materials and chemicals companies need two things:
- An easy way to get legacy data into a centralized database
- A way to structure the data in a common format that has the right mix of flexibility and standardization
Citrine Informatics has overcome this challenge by:
- Developing a graph-based data format (Graphical Expression of Materials Data) that easily accepts new data
- Seamlessly handing data from business units using different units and naming conventions
- Enabling data ingestion through both drag and drop of an Excel sheet and the use of data pipelines via the python API.
3. Converting Information into Machine-Readable Data
Materials data, including molecular formulas, is more complex than simple text and dates, etc. The letters and numbers themselves in a chemical formula are not what’s important, it’s what they represent that is critical to analysis.
Citrine Informatics has overcome this challenge by:
Developing a chemically-aware platform that automatically converts notation representing chemical formulas and molecular structures into 127 different descriptors of that molecule. This enables a deeper understanding of the fundamentals that are driving performance in a formulation.

4. The Prediction Task Is More Complex Than Classifying Cats and Dogs
Many typical AI applications involve pattern recognition: a matching of common cases. Based on a large set of already-classified animal photographs, can a model accurately predict whether the next photo is a dog or a cat? R&D scientists are not interested in finding existing common cases, but rather exploring higher performing materials that push the limits of existing structures and properties.
Citrine Informatics has overcome this challenge by:
Developing proprietary methods to efficiently explore the search space using Sequential Learning. This enables customers to extrapolate beyond current data in incremental steps using the fewest possible experiments.
5. AI for Materials Needs to Understand Physics
The laws of physics and chemistry are not applicable in typical machine learning applications. In the materials and chemistry space, they have to be obeyed! Understanding all the rules governing the space you work on is an asset that can be used to narrow down the candidates you are exploring, or increase the accuracy of a machine learning model by programming in known relationships between parameters and results, leading to better predictions and quicker results.
Citrine Informatics has overcome this challenge by:
By making the Citrine Platform easy to use, requiring no coding or data science knowledge to get results, we have enabled product experts to work directly on the platform, adding their knowledge of physics and chemistry and thereby accelerating product development.
6. Failed Data Is Rare
Sample bias in datasets is common across all AI applications, including materials and chemicals. One form of this in particular affects materials and chemistry. Machine learning models require data that includes a range of measurements. It needs failures as well as successes; without it, the model will never predict a failure. Scientific publications tend to bias toward successful results, and data from previous failed experiments is often not available. AI performs best with a diverse set of data.
7. Uncertainty Is Critical
In many commercial applications of machine learning, like consumer preferences or business intelligence, uncertainty in AI predictions has little consequence. For example, a retailer would not want to include “we are 60% certain that you’d like to buy these shoes” in a marketing newsletter. In fact, this might be detrimental to sales. However, in the materials industry, product developers need to know the uncertainty in model predictions in order to act confidently when deciding which experiment to perform next, as it often requires a large investment in time, money, or resources.
Citrine Informatics has overcome this challenge by:
Citrine’s research team published a ground-breaking paper on how to estimate uncertainty back in 2017. Doing this well is the key to making good strategic decisions on what experiments to take to the lab next.
8. AI Models Need to Be Understood by Domain Experts and Your R&D Team, Not Just Data Scientists
As R&D is digitized in the materials and chemicals industry, it is important for scientists to be able to scrutinize and sense check models. Additionally, new scientific insights or IP created via an ML-driven approach need to be shared among the researchers in order to facilitate knowledge transfer and up-skill the team. In other words, a typical “black box” machine learning software is not fit for purpose.
“We understand our own laboratory more than before. It’s fun to work in this way.” Oliver, Technical Application Lead
Citrine Informatics has overcome this challenge by:
Our emphasis on explainable AI, enabling researchers to learn from the AI models as well as teach them, is what makes the platform fun to use. Product experts learn more about their own domains and get “Aha!” moments as an unexpectedly important feature is uncovered.
9. Scalability
Many materials and chemicals companies now have a centralized data-science team who is capable of structuring data, training a machine learning model, and communicating results to product developers on a project.
However, we’ve seen companies get into trouble as they attempt to scale this effort to multiple projects or multiple business units. When scaling a materials informatics effort, companies have to consider database and code maintenance, version control, model deployment, security and access control, data management, continuous deployment/continuous integration pipelines, model and data reusability, and infrastructure configuration—all of which require a significant investment in software engineering.
Citrine Informatics has overcome this challenge by:
From the start, scalability was built in. Not just in the scalable graph-based data model that accepts varied data and unifies it, but also in the modularization of search spaces and AI models, that enable easy reuse across teams. This allows for example teams working on similar chemistries for different applications to reuse models but tweak the target properties.
10. Security: Protecting Your IP
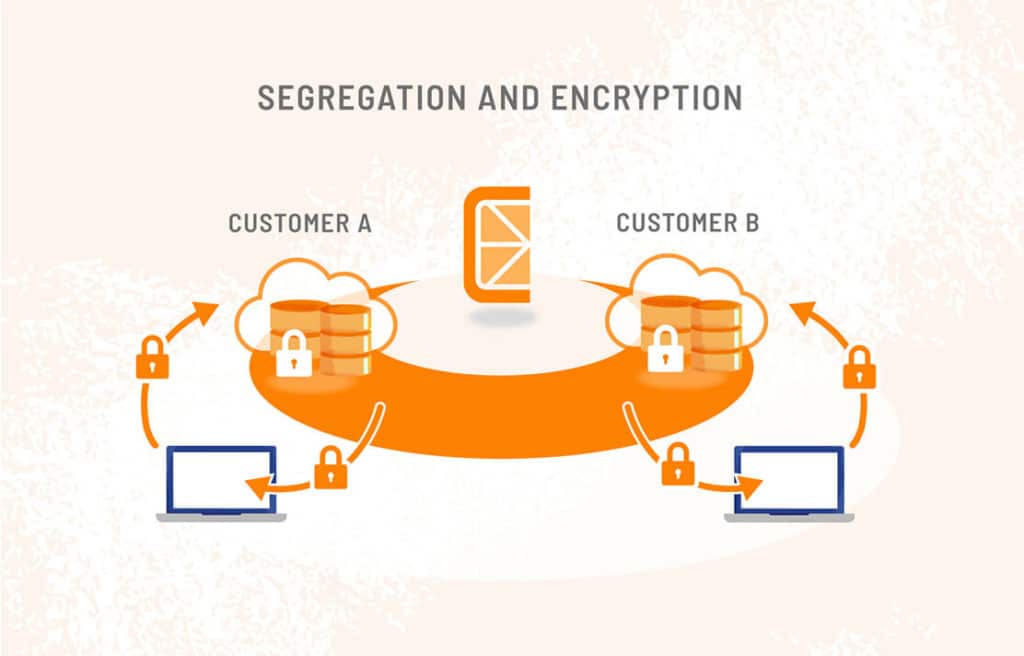
Data security is of utmost importance in the materials and chemicals industry. Unique formulations recipes, processing steps, and test/characterization data are what give materials and chemicals companies a unique competitive advantage. Digitizing this data opens up new avenues for data loss or unauthorized access of IP. Materials and chemicals companies should carefully consider how they store, share, and manage their materials data when exploring AI applications.
Citrine Informatics has overcome this challenge by:
Citrine Informatics took security seriously from the start. We are ISO 27001: 2022 accredited and you can read our policies and review our monitoring in the trust center.
Ready to transform your R&D processes and achieve breakthrough results? Discover how Citrine Informatics can help you stay ahead of the curve.