
Executive Summary
ACCELERATED INNOVATION
50+ solvent blends satisfied all end-customer constraints in 5 months
IMPROVED PERFORMANCE
150+ improved solvent blends discovered from over 100M candidates
The Challenge
Solvent blends are needed by many different industries, with different end uses and target characteristics. Identifying suitable solvent blends through a process of synthesis and testing can be costly and time consuming.
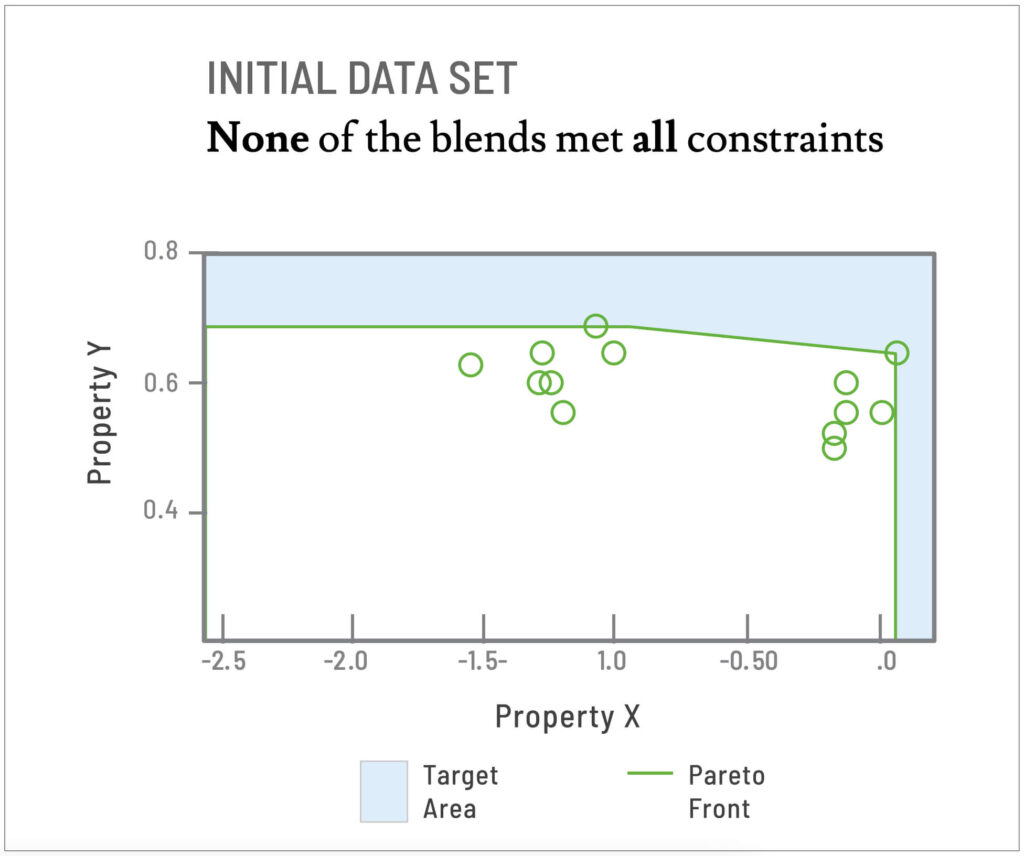
The challenge for Citrine was to help Showa Denko target their testing efforts on candidate blends that had the highest chance of success–those that met all the downstream customer constraints and maximized the target properties. This was particularly challenging because none of the solvents in the initial training data set met all constraints and there were 850M+ possible combinations of the Showa Denko’s in-inventory solvents.
The Approach
A set of ~380 solvents were identified by the expert Showa Denko team as those that should be considered in formulations. The domain knowledge of the team was incorporated into a set of rules that could be used to evaluate the >100M valid solvent blends (the design space). The initial data set of previous test results for solvent blends was ingested into the Citrine Platform and used to train the first machine learning model. From then on, an iterative approach called Sequential Learning was used to improve the model accuracy and find good candidates. This methodology is the next generation of Design of Experiment. Making sure that each experiment delivers the most information possible.
Sequential Learning is a process where an ML model predicts the properties of a chemical and the uncertainty surrounding the prediction. These values are used to suggest which candidate chemicals should be tested next. These are chosen either because they will help improve the model or because they are thought to be candidates with great properties. Candidate chemicals are tested and the data from these is then included in the training set. The model makes new predictions and the process is repeated until great candidates are found.
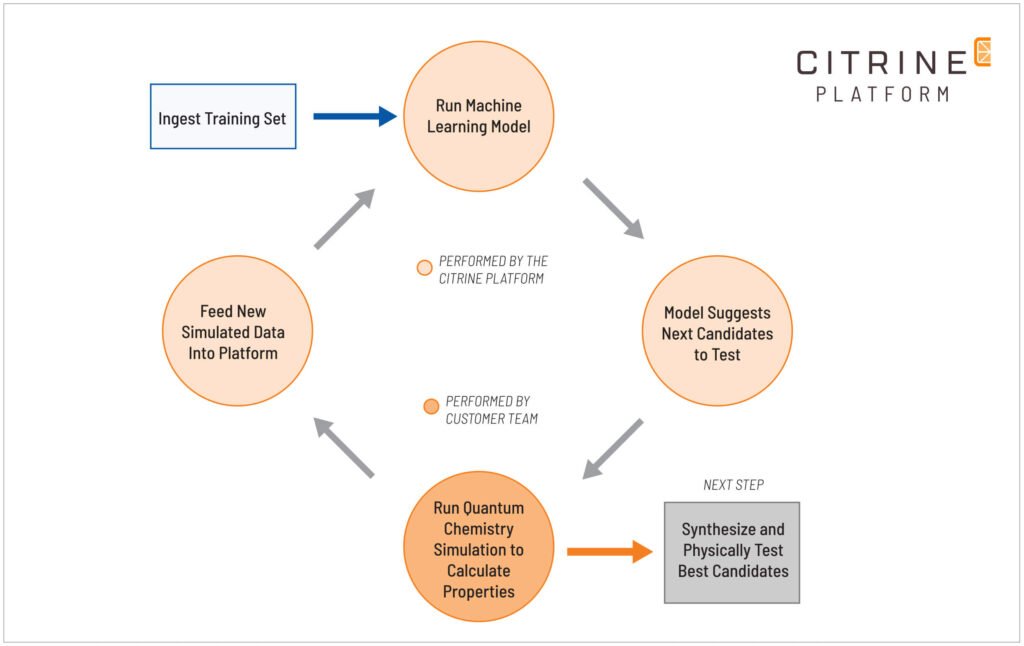
In this case, instead of physically testing the suggested candidates, their properties were calculated using quantum chemistry simulation. Sequential Learning and simulation were used in tandem to quickly generate possible solvent blends and gather property data. Five iterations of Sequential Learning were completed to discover the best candidates for final synthesis.
The Results
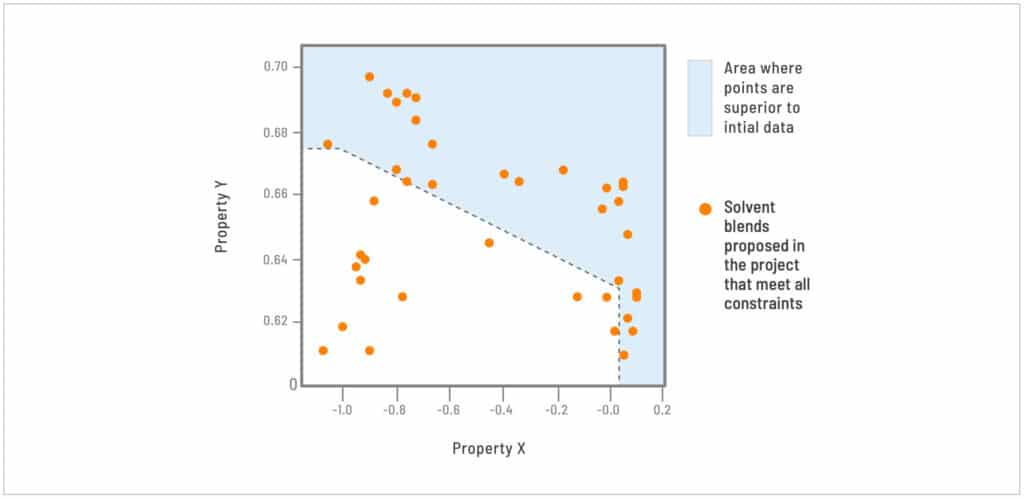
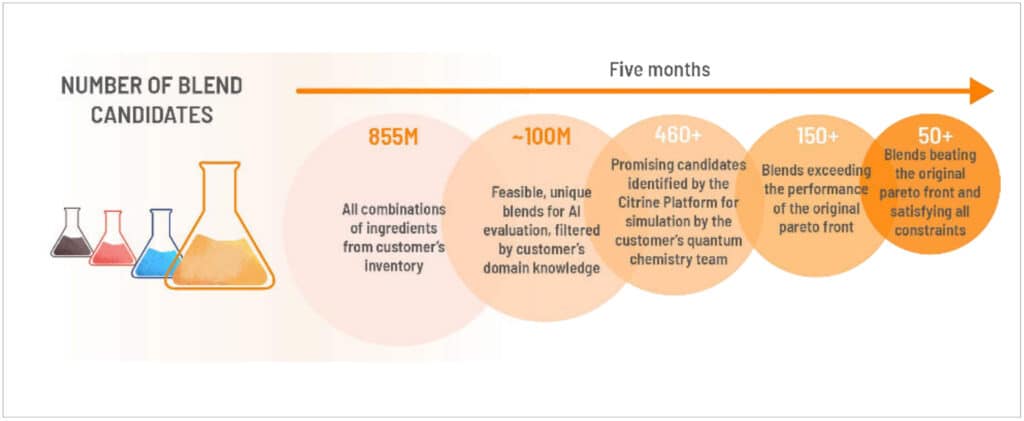
Just 5 months after starting the project, Citrine and Showa Denko had identified 150+ solvent blends that beat the original property pareto front (i.e. better than all previous results), based on quantum chemistry simulations. Over 50 of those blends satisfied all the project constraints. Showa Denko can now review the cost, risk, input materials, or constraints and property profiles of these potential blends and synthesize and perform confirmatory tests on their preferred candidates with their downstream customer.
Future Work
The Citrine Platform uses a modular graphical model so that components can be reused by future projects. Should the downstream customer requirements change, or a separate end-customer(s) request a similar project with a different requirements or trade-offs, the machine learning model could be quickly adapted to new target properties.
