
Xavi Linn, our Principal Data Engineer, has worked with dozens of chemical companies to help them get their data ready for AI. Learn from his experience.
We’ll explore smart data practices at three critical levels: organizational strategy, team management, and individual research projects. Whether you’re starting with minimal datasets or managing complex data infrastructure, these proven approaches will accelerate your AI transformation journey.
The Reality of Chemical Data Landscapes
Success in AI doesn’t require perfect data infrastructure. Our experience across hundreds of implementations reveals that most valuable AI projects start with modest datasets and grow strategically.
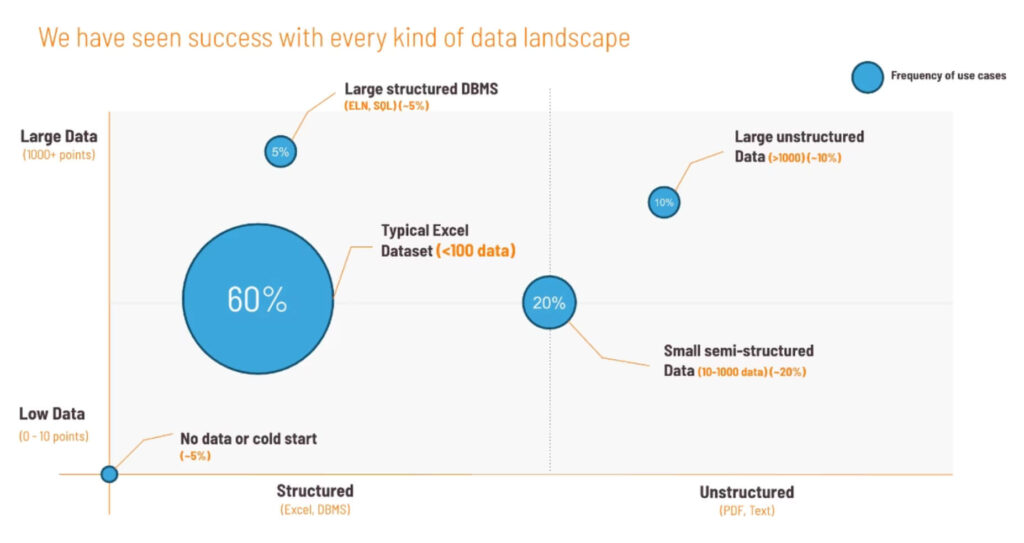
The majority of successful AI implementations begin with simple Excel datasets containing fewer than 100 data points. This demonstrates that transformation doesn’t require massive data infrastructure investments—it requires smart strategy and the right tools to extract maximum value from existing information.
Strategic Data Infrastructure Development

Start Small, Show Value
Begin with targeted initiatives that demonstrate immediate value to product teams rather than large ELN system projects that lack user motivation.

AI as Motivator
Researchers adopt better data practices when they see AI’s direct benefits to their work and research outcomes.

Empower Domain Experts
Enable those closest to the work—they know what’s most relevant data and can drive adoption from the ground up.
The key to successful data infrastructure lies in creating clear incentives, allocating dedicated time for data efforts, and implementing user-friendly platforms like Citrine. These platforms should minimize friction in data capture and upload, provide intuitive interfaces that scientists can adopt without slowing down their research, and deliver quick feedback on data discoverability and usability for AI. Since scientists are focused on doing science, systems must be easy to use and add immediate value to their discovery process—rather than feeling like extra work. This is why Citrine is investing in tools to move the scientists’ work from data entry to data validation, as data entry gets handled by advanced AI tooling. We have also found that product experts value the insight they gain from seeing which inputs and and features of chemicals are having the most effect on the final properties they are interested in. Scientists love to know why. Getting more information about why is a huge motivator for experts to spend time on data.
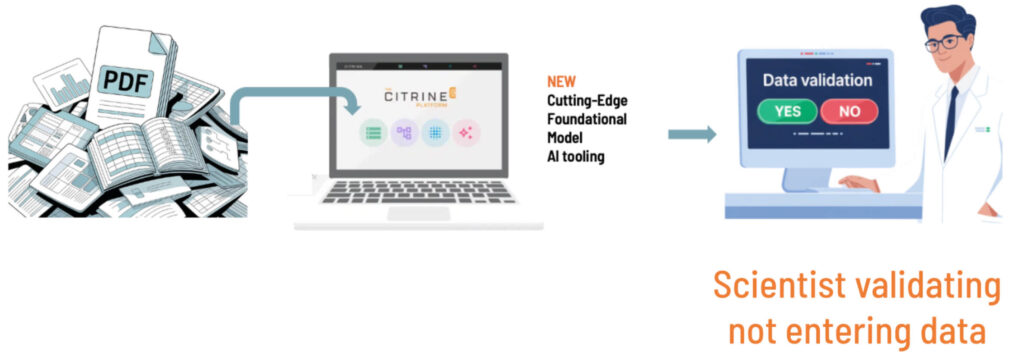
Robust infrastructure requires thoughtful implementation and ongoing maintenance. Data is inherently high-entropy, and the challenge lies in wrangling it into lower-entropy states that make datasets easier to discover and more effective for AI applications.
Empower Domain Experts
Domain expertise in chemistry and materials is also critical when designing infrastructure that supports the unique access patterns scientists require in R&D processes. I highly recommend consulting with experts in this area to ensure you start on the right track. I’ve worked with many customers who adopted data infrastructure without careful consideration, invested thousands of hours in rollout—only to fail because the systems were not fit for purpose or lacked the incentives needed to generate ROI.
Start Small
One key consideration in building your data infrastructure is that you can start small—perhaps with a single scientist or one research division—as long as you understand how that data will connect to a broader data management strategy. Establishing an interdisciplinary team of scientists and data experts is essential for creating governance that enables integration across many disparate sources. A proven approach is to define ontologies—essentially a shared vocabulary of terms and their relationships—that are both generalizable and scalable across the enterprise, paired with data capture mechanisms that align with those ontology definitions.
What Makes Data AI-Ready?
Connected
Inputs and outputs clearly linked with unique material IDs that enable traceability and relationship mapping
Contextualized
Full experimental lineage with rich metadata capturing methodologies, equipment settings, and environmental factors
Diverse
Variety of examples covering the solution space, including both successes and failures for comprehensive learning
Structured & Normalized
Consistent formatting with standardized units and normalized values across batches and experiments
Relevant
Clear objectives defined upfront—know exactly what you’re trying to measure, optimize, or predict
Pro Tip: The Citrine Platform helps automate much of the structuring and normalization process, allowing scientists to focus on research rather than data formatting.
Supporting Teams in Best Data Practices – re-frame your understanding of bad data.
With AI systems, there is no such thing as “bad” data—as long as it is physically sensible and accurately reflects what happened in the lab. Both unstructured spreadsheets and failed experiments are valuable data sources for AI. Unstructured spreadsheets can be transformed into structured formats, and failed experiments provide critical information about how certain combinations of processing and composition lead to undesirable outcomes, depending on the optimization targets. Historical breakthroughs like penicillin remind us that so-called “failed” experiments often contain the seeds of major discoveries.
To best support your teams in adopting data best practices, recognize that this is a matter of change management, which requires both time and effort. There is no hiding the fact that adopting best practices in data management is an investment. With tools like Citrine, you can invest in data best practices that not only enable short-term discovery of materials for immediate needs but also build long-term habits that ultimately allow AI-driven tools to scale across the organization.
Create leadership opportunities within your organization to champion the adoption of data best practices and AI workflows. We are firmly in the era of data and AI, and workflows must evolve to integrate these technologies in order to remain competitive. By developing initiatives that empower both leaders and practitioners, you not only build momentum for sustainable adoption and lasting impact but also create valuable professional development opportunities.
Recognition Matters
Explicitly reward and recognize employees who create high-quality data and enable its use across projects.
Give Them Time
Allocate dedicated time to learn new systems and perform thorough data curation without rushing.
Data Governance
Implement standards for security, privacy, and lifecycle management with regular process checks.
Identifying Critical Data and Features for Success
Successful AI implementation requires identifying the right variables that drive outcomes in chemical processes. The most effective approach combines domain expertise with data-driven insights and iterative learning.
Domain Expert Input
Leverage chemists’ knowledge to identify likely influential variables based on theoretical mechanisms and experience
Statistical Analysis
Use data analysis tools and feature importance charts in the Citrine Platform to identify key relationships
Iterative Testing
With each batch of experiments, retrain your AI model and review feature importance to prioritize data acquisition efforts
Be Agile
Learn as you go rather than trying to optimize all features before starting—this is a new paradigm requiring adaptive thinking
The key insight: You already have enough data to begin your AI journey. Start small, show value, and leverage the Citrine team’s decade of experience in rolling out AI solutions across the chemical industry.