An interview with expert Principal Data Engineer Dr. Lenore Kubie, whose role is to help companies get their data AI-ready and available in the Citrine Platform. Data is the first step on the road to leveraging AI and Lenore’s deep, 10-year experience in data management benefits our customers.
How many projects with large multi-national organizations have you worked on now?

I’ve had the pleasure of working with eight of our larger multinational customers who produce a range of materials from plastics to ceramics. Even across these diverse materials classes we see a lot of commonality with their data pain-points and goals. Digging in with these customers to understand their current dataflows and challenges, and coming up with realistic pathways to help them achieve their goals is an enjoyable part of my role.
Do companies typically have their data ready and you just jump in to create pipelines to the platform?
No, not so far and that’s okay! Materials and chemicals data are complicated. We have seen everything from practically zero data management to companies with several different data management systems left over from various mergers, which lead to data being siloed in legacy systems.
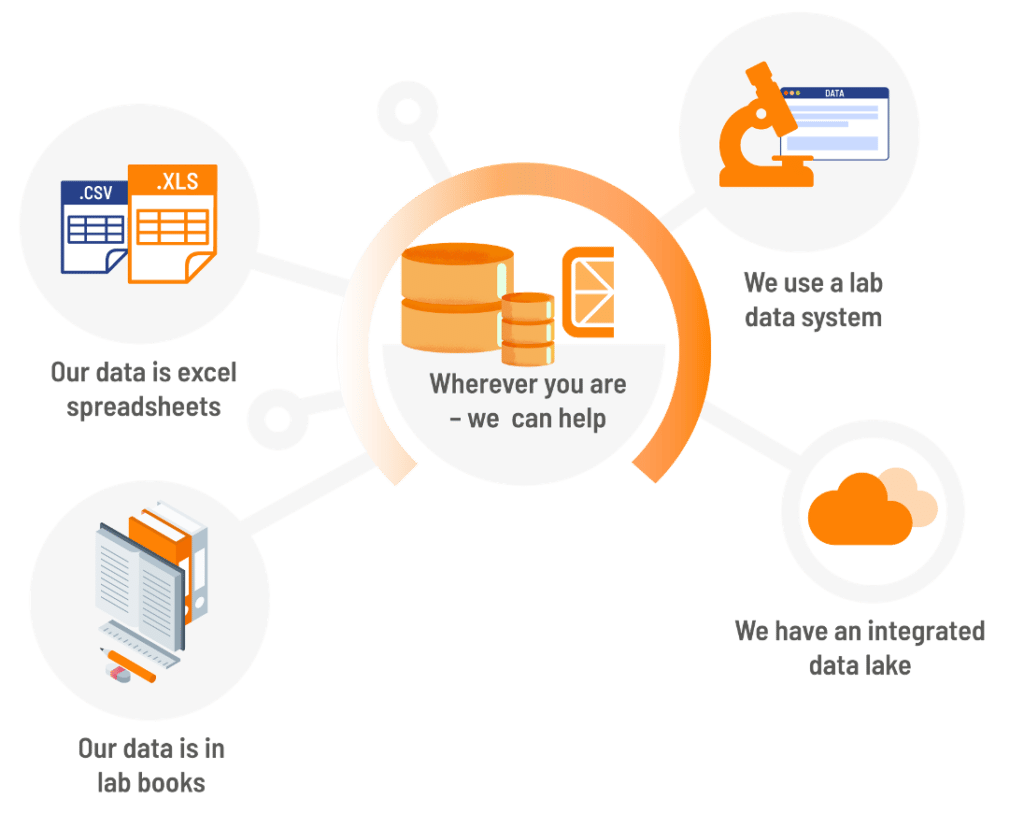
How do you decide which data to get “AI-ready”?
We have a lot of experience looking at these data sources and scoping the time and energy it would take to get data “AI-ready”. Our customers know best which data sources are most relevant to their business objectives. Together we can help customers make informed decisions about which data are worth investing in preparing and in what order. Some data, of course, are easier or less expensive to simply regenerate depending on the time and cost to create and test samples.
Is all the data in a company equally valuable?
Generally, we find that production data are stored in the cleanest and most structured way. However, production data are only capable of teaching AI about performant materials. R&D data have more variation in what was tried. These highly varied inputs and outputs are excellent “brain-fuel” for our AI models as they teach models both what works and what doesn’t work. It’s important to remember that if you train an AI model on only things that work well, as far as it knows anything will work well. Unfortunately, R&D data are generally less AI-ready for a myriad of reasons. All together, we have to take a value-driven approach to deciding where to spend our time in preparing data for AI.
Why isn’t there lots of AI-ready data already in Materials and Chemicals companies?
Chemicals and Materials data are not as easy to organize as many other types of data. Finance transactions or shopping purchases generate millions of data points a day in very standard formats. With materials and chemicals data you are lucky if you have 100 data points and some of those will be in the form of chemical structures or charts from testing equipment. Traditionally, materials and chemical data storage systems were designed for regulatory compliance, not for AI. Standardization wasn’t enforced, and images and charts were simply attached as a PDF. AI adds new requirements. To capture machine readable, structured data systematically, data management systems need to evolve. Now that the value of Materials and Chemical Informatics is proven, we see our customers investing heavily in reworking their data workflows and systems to support this AI future.
Any advice for companies hesitant to start getting their data in order?
I know how daunting that undertaking can be. So, here is some practical advice.
1. The first step is to stop the bleeding
The experiments your team carry out now and in the future are likely to produce data that are more valuable to your business in the future than badly labeled historical data. The sooner you can start capturing data in a structured, standardized, and linked way, the sooner you can start leveraging AI.

2. Systems need to work for your employees and your goals
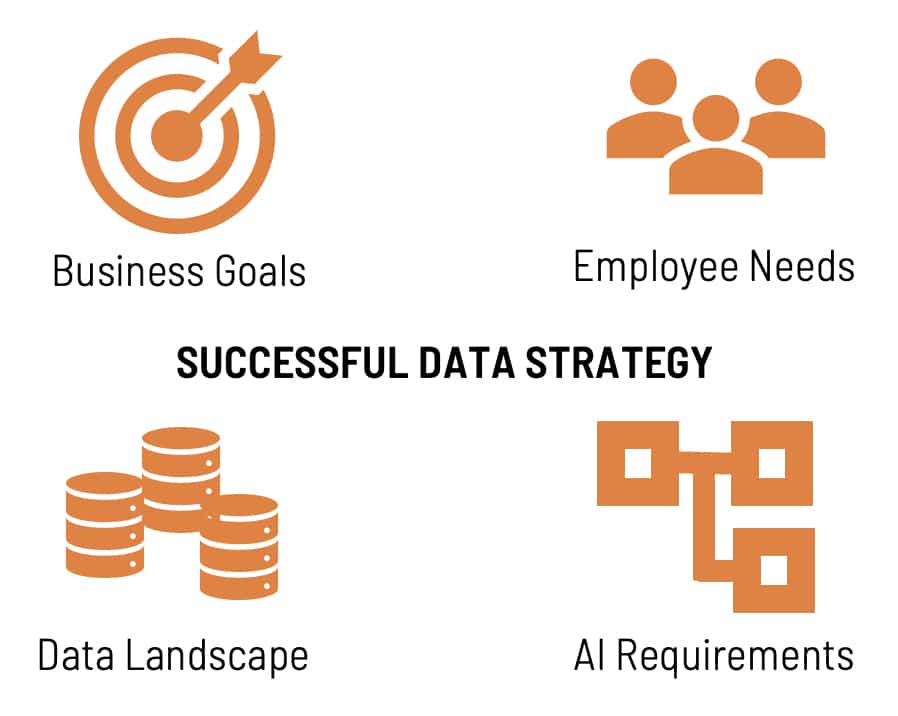
That leads us to figuring out what an ideal data workflow looks like. Data workflows and storage systems need to work for your employees and your goals. It’s important to understand the requirements of those inputting data (making it easy to do well) and those using the data (capturing the right data in the right format). Work with your internal AI teams (if you have them) or your preferred vendor for AI to choose the right data structure and make sure you understand what lab technicians and researchers like and dislike about their current data input workflows. Also, make sure your business objectives, such as KPIs, are consistent with the changes you are hoping to achieve.
3. Nail it and scale it!
By starting with a single high-value project or business unit, you can test and refine your decisions while keeping the scope from feeling too overwhelming. You will learn a lot about the true state of your data, the capacity of the team overseeing the overhaul, and how new data systems work. Find out about these on a small project so you can properly plan large scale projects.
How does Citrine help companies get their data ai-ready?
Citrine takes a holistic and customized approach to helping our customers develop a data strategy that will work for them. We have experience helping startups wanting to “get it right from the beginning” as well as large multinational organizations needing an assessment of decades of historical data stores across the globe. Our approach and deliverables differ for these different scenarios.
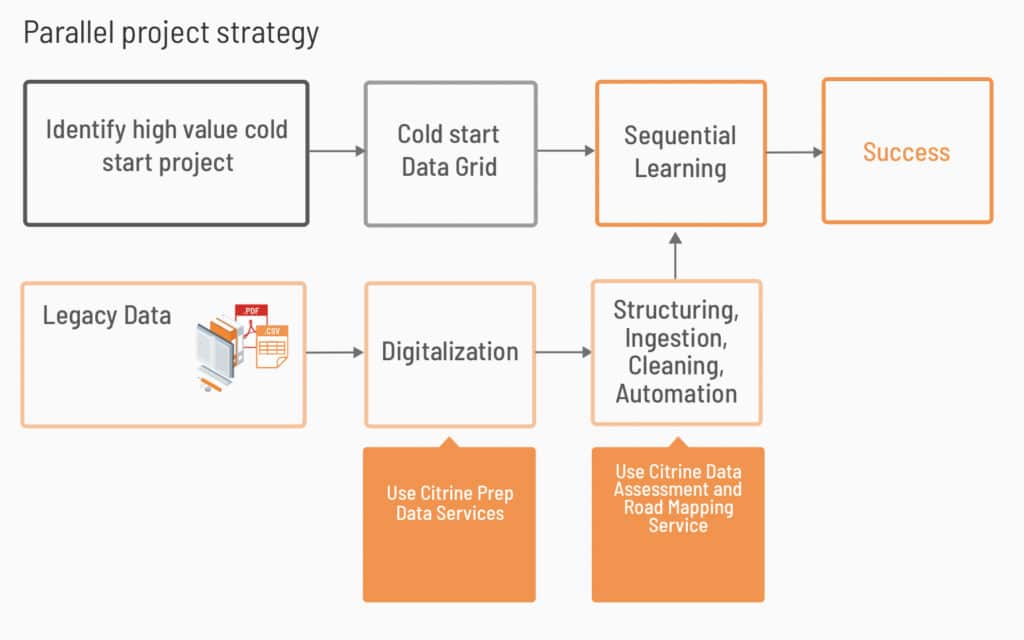
We offer two services – Data Preparation, and Data Assessment and Roadmapping. Data prep tackles historical data that is not yet AI-ready (e.g., PDFs, messy databases), and Data Assessment and Roadmapping is a process where we come up with a data strategy with the input of everyone from executives of the company to technicians inputting data. This enables us to highlight any areas where the long-term vision of executives is misaligned with the way data systems are currently being used, and outline a value-driven approach that will bridge the gap between where a customer is today and where they would like to be in the future.
If you could ask our customers to do one thing, what would it be?
Make sure your inputs are linkable to your outputs! So much can be done to clean historical data. What can’t be repaired are totally missing links between data. A few times, we have unfortunately seen the situation where how samples were made, and measurements done on those samples are stored in two different systems, with nothing to link the two together. No one, not even the researchers, can go back and piece it together. Check your data workflows and make sure there is some way to link your key inputs and outputs even if it would be a fairly manual process (though a direct link is always better).
Want to be a part of the action?
Check out our Careers page!
Want to stay informed about happenings at Citrine on a quarterly basis? Sign up for our Life @ Citrine newsletter HERE.